
Data Migration Done the Right Way
Introduction
Every time a company decides to migrate their business systems and processes to Salesforce one thing is certain: the question of data migration will come up. Some companies use spreadsheet documents like Google Sheets or Microsoft Excel to organize its business operations, while others opt for a CRM or a custom solution. No matter the situation, you will most probably find great value from your historical data and you should always migrate it, unless you are facing legal restrictions.
Although the migration of existing data sets sounds like a simple job, in reality it is very complex and might be the most underestimated task in complexity and quality of execution. There is very little you can reuse from previous data migration projects, since every project has completely different data sets (table names, column names/types, table structure/relationships and different databases/files) coming from different environments. So what can we do?
An Example
Imagine you had a custom solution and decided to move to Salesforce. You’ve had discovery meetings with your implementation partner and started adopting Salesforce. Already at this stage, your partner should think about the data migration process. Questions emerge:
Which processes are they replicating in Salesforce?
Which processes are new?
How do we fit the old data schema into a new one?
Salesforce has its own way to organize records that might differ from your old system. You might have had three different data tables, one for each kind of customer, whereas now all of those will be stored in Salesforce in a single object (the Salesforce equivalent of a database table) and distinguished by a record type. In this example, the three tables will be merged into one Salesforce object, but there are also scenarios where we might have to split one table into two objects. The perfect example is again where we would have to split a customer and contact details into the Account and the Contact objects.
What about the Products and how will the pricing be implemented? Will you be using Pricebooks or Configure-Price-Quote (CPQ)?
For importing data, Salesforce offers some assistance in the form of their client application called Data Loader which is capable of dealing with simple CSV files, which you might have to prepare in tools like Excel. The main issue with this approach is that you most probably are interested in not only migrating record tables, but you also want to preserve the relationships of the source data structures in Salesforce.
Using Data Loader for this task requires a lot of manual data preparation in programs such as Microsoft Excel, which can be both time consuming and prone to errors.
Now imagine: you have managed to import all of those tables into Salesforce and it took you two or three weeks. Now somebody notices that some columns were omitted and that they have a significant impact on the analytics. Now you have to repeat that whole process again. Two weeks later, somebody else notices that the historical order analytics do not match up in the old system and new one and you trace it back to a few clients not being imported and so now you have to perform this whole process but only for a smaller subset. Writing an Excel formula takes the same amount of time for a 100 records as it does for a 10 000 records.
Somehow you were able to solve all of those problems (again it took a couple of days/weeks) and then comes the next issue. Since you’ve started the whole migration process, the old system has generated new records which are now missing in Salesforce since the systems have to be able to work in parallel and need to stay in sync. Just because you are migrating data, you are not going to stop your company from working.
Since scenarios like this are very common in a data migration endeavour and hundreds of things can go wrong that might require a complete or partial reload, we have established a general approach that covers all possible scenarios. For this purpose we have compiled a list of key aspects of any data migration, which takes on the nature of a data integration if performed in a scheduled continuous delta-load approach.
Data Sets
The first step is always to determine what needs to be migrated, the mapping between the old and new data structures, and their relationships and dependencies. Just as you cannot build a roof before the walls, you also cannot import the sales data without importing the client list first.
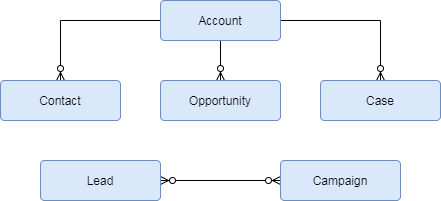
Using this analysis you can build up a relational diagram from which you will be able to determine the exact order of migration execution. The first sets to be migrated will be the ones that have no dependencies. In this example you will be able to load the contacts after you were able to load the Accounts. But at the same time you are able to load all Products since they have no prerequisites. As soon as all of these data sets are loaded you can proceed to migrate the sales data sets in the form of Opportunities, Quotes and Orders. Usually the first object you will want to migrate is the set containing the users.
One very important step is to immediately classify the data sets into two categories. The first category is the Master data set, which represents the data that rarely changes and serves as the basis of your business processes. This category might be represented in your case as the list of the Product families you offer or a list of your warehouses... typically the data that you would represent in Salesforce as a picklist. If there is a reason for it (like for instance being used in many objects, having additional descriptors used in other processes like for instance warehouse size or Product family production volume or related data sets used for analytics purposes like orders for specific warehouses) then it might be worth to consider migrating it as a Salesforce object on its own.
The second dataset category are the typical records that are created by day to day operations, typically represented by your products, clients, contacts, orders, etc.
Timing
Data migration has to be very well timed. It is essential to start it at the right time but also coordinate it with the implementation. The perfect scenario would be to perform the migration after all of the business processes have been implemented in Salesforce and you can migrate all of the data accordingly without fear of changes, but in most cases this is not possible from a time management perspective. What we always recommend is to determine, during the discovery and design phases, the correct order of implementation for the whole project.
As you make a list of implementation milestones you can make assumptions on when each part of the migration needs to be executed. The milestone discovery will typically follow up with the business process development, testing, workshops and migration. The picture might be even a bit more complicated with outstanding integrations.
We always try to set up several stages of the migration process in order to separate the completed migration steps from the ones still in development. One environment for development, one for system integration testing, one for user acceptance testing and finally one for production. Depending on the situation we might either migrate all datasets at once or in subsets.

Requirements often change and consequently solution modifications will be required. All of our migration projects are implemented to be flexible by utilizing parameterized configuration files. This way we can target development to isolated environments but also modify the logic of the migration procedure by only changing a few variables written in a file. E.g., if we wanted to perform a migration to a different environment, all we would need to do is to change the source and destination parameters in the configuration.
Data Set Mapping
This step is always essential. We typically plan this step with the help of a spreadsheet editor. We define each spreadsheet as one dataset to be migrated. Inside each spreadsheet we define the name of the source table and its attributes. Afterwards we relate them to the destination Salesforce object and related fields. We also specify the transformation in question and some other descriptors, such as if it is mandatory and which type of data we are mapping it to.

What we gain from this is a single document, visible by everyone involved, that serves as the single point of truth on which database table needs to be migrated into which Salesforce Object using which transformations.
Technology
It may be tempting to try the Data Loader approach (or something similar via a plugin to Excel or browser) or perhaps write a quick and dirty custom code solution. Since data migration is a mission-critical step, quick and dirty solutions should only be used as a last resort. In order to maintain a level of quality, we use well established Extract-Transform-Load (ETL) tools for data migration such as Informatica or Talend.
Utilizing ETL tools adds both robustness AND flexibility to the process. They allow us to develop a workflow-based, so called, migration flow process that the user only needs to launch and all necessary data transfers and transformations are performed the same way, every time. The person executing the migration never has to manually look up any information, perform data joins or filtering. The developed data migration process performs all of these operations itself. Everything the user needs to do is to start the migration process and lean back to observe the transformations being performed in front of them.
The benefits of using the ETL tool approach are numerous and give us the opportunity to perform the migration in the best possible way:
Variety
As with most things in life, it doesn’t make much sense to reinvent the wheel. ETL tools come with a variety of components that can perform the push/pull data operations with various environments. List of supported data sources and destinations includes, but is not limited to, many RDBMS applications (Oracle, MSSQL Server, MySQL, PostgreSQL, IBM DB2...), SAAS systems, cloud services, CRMs, ERPs, MS Active Directory, various file types and others. They also support additional operations like establishing SSH sessions, sending emails and providing reporting services.
All of those services are already implemented as components and all we need to do is to use them. We do not need to write any code, but we use components that are easy to oversee and maintain.Complex migrations
As soon as you start migrating data you will need to resolve the identifiers of dependency. You will have to find which old contact entry relates to which new Account in Salesforce. We avoid this manual step in this way so that we create a workflow that will perform the retrieval of accounts and crossmatch it with the source data. Normally this does not sound like a huge problem, but when you consider that you might need to export five million records, which can take half an hour, then this step can easily add up to a substantial amount of time spent on waiting. Now imagine you need the records from a dozen more objects as well.
Over time, the dataset might get new Contacts or lose some of them, yet the migration process is always working with the live data set without the need for manual data manipulation by the engineer. We implement this behavior one time, and it performs the same operation always, no matter which data or environment is involved.
Another aspect that we are able to perform using this approach is that we are not limited only to data from CSV files but we can simultaneously perform the migration from any database, any file format, and a wide variety of cloud services.Ease of maintenance
As soon as we introduce a new field to be migrated, all we need to do is introduce it in the schema of the workflow and it would propagate through each step. The mapping and conversions are truly minimal.
Our migration workflows also include full versioning capabilities, meaning that we can bring back an old version of the migration at any given point in time.Variety in execution (single job, sequentially)
We typically set up the whole migration procedure in a way that it can be launched and perform the whole migration on its own, without any user input or monitoring, while also having the capability to manually launch each workflow on its own.
When launching the job, we always implement it in a way that we first pull and cache the data from the source system and then proceed to transform it. If an unexpected situation arises we are able to easily fake (mock) the input data for test purposes. This feature is extremely useful when unforeseen consequences happen and we are able to quickly mock test data to perform an analysis and deliver a solution.Reporting
If a tree falls and there is nobody to hear it, did it fall at all? The same can be said about data migration. How do you know that something was done, if you don’t have the information about it or it’s success rate? We always advise setting up procedures on our data migration workflows so that each of them creates detailed reports for each step.Delta Sync
Sometimes the amount of data or organisation is too great for it to be loaded in a single attempt so it can be advisable to do it in phases. It is essential then to enable the possibility of performing a differential (delta) load, meaning only the new and modified items are being transferred from the source. It enables us to sequentially load them, but also load any newly created records as the time progresses while the old system keeps running in parallel.
The great benefit of executing procedures like this is that the record count drops down significantly and the whole migration process is reduced significantly.Integrations
The same data migration workflows we create can be utilized to work as a data integration platform, in which case, we add an orchestration workflow on top of the data migration. This one makes sure that the migration jobs execute in the proper order, but also to perform the setup of the execution run itself in the form of compressing and storing the temporary files into the local history, emptying the cache as well as sending notifications in case of a job failure. The last step the user needs to complete is to schedule the execution of the integration job on an hourly or daily basis.
General Guidelines and Considerations
During the migration, there are several key aspects that fall into the “nice to know” category:
Every object in Salesforce that needs to be migrated, should get an additional field serving as an External Identifier. We use it either to set up a custom key, by which we will be able to uniquely identify it or we use it to store the old Identifier from the Source System. We also suggest always naming the field the exact same way because it increases the reusability of certain workflows.
Some system objects (e.g. attachments) cannot be extended with custom fields, so we find other ways to be able to uniquely identify each record, even when we upload files into Salesforce, which are stored as records.
The user performing the migration should have System Administrator privileges (best is to have a separate profile or permission set for this case), with which he would be able to perform some tasks that only he should be able to. By default, it is not possible to modify the creation timestamp in Salesforce, but by changing the profile settings you can get this possibility to be able to explicitly specify the date when the record was created or modified. What you cannot have an impact on is the history tracking. At this point in time you are not able to inject the history tracking records (we hope Salesforce considers changing this). You cannot specify the whole changelog of the records in question. The only thing you could do is to simulate all of those changes in the original order.
Following these guidelines and taking all of those aspects into consideration can greatly increase the chances of a successful data migration. There are some limitations to what can be achieved and sometimes you might have to make compromises, but this is mostly in the case of special Salesforce objects that inherit some special behavior (OpportunityProduct, Event, etc.).
We hope we were able to clarify the intricacies of a data migration endeavor and its best practices. As it is in life, the whole picture is never purely black and white, but shades of grey depending on the situation at hand.